
착해지는 중 입니다.
[SQL] 그룹함수 본문
###그룹함수
그룹에 대해 실행되는 함수
그룹당 하나의 결과 산출, 그룹의 컬럼을 함수의 입ㄺ으로 넣어준다.
GROUP BY절 생략 ( 재료집합 전체를 하나의 그룹으로 간주)
숫자 데이터만 처리할 수 있는 그룹함수
SUM(합계), AVG(평균), STDDEV(표준편차), VARIANCE(분산값)
-- SUM: 지정된 열의 모든 값을 더합니다.
SELECT SUM(sale) AS total_sales
FROM local_sales;
--AVG: 지정된 열의 평균 값을 계산합니다.
SELECT AVG(sale) AS average_sales
FROM local_sales;
--STDDEV: 지정된 열의 표준 편차 값을 계산합니다.
--분산 값의 제곱근? 평균을 중심으로 값들이 어느 정도 분포하는지를 나타내는 수치인 표준편차를 지표로 사용
SELECT STDDEV(sale) AS sales_stddev
FROM local_sales;
--VARIANCE: 지정된 열의 분산 값을 계산합니다.
--주어진 범위의 개별 값과 평균값과의 차이인 편차를 구해 이를 제곱해서 평균한 값
SELECT VARIANCE(sale) AS sales_variance
FROM local_sales;
--부서이름의 평균길이
SELECT AVG(LENGTH(DEPARTMENT_NAME))
FROM departments;--평균길이
--부서이름의 평균길이를 소숫점이하 둘째자리에서 반올림
SELECT ROUND(AVG(LENGTH(DEPARTMENT_NAME)),2)
FROM departments;--평균길이반올림
숫자, 문자, 날짜 데이터 처리 할 수 있는 그룹함수
MIN, MAX, COUNT
그룹함수 적용 불가 데이터 타입
LONG ,
LOB 타입 : 테이블을 여러개의 컬럼으로 만들어주고 인덱스도 만들수있다.WHERE절에서 사용할수있다.
LONG대신 사용가능. (4000바이트 이상일경우 LOB 사용해도됨.)
SELECT * FROM T_LONG;
DESC T_LONG
SELECT SUM(C1), COUNT(C1) FROM T_LONG;
SELECT MIN(C2) FROM T_LONG;--그룹함수 사용불가
SELECT COUNT(C3) FROM T_LONG; --그룹함수 사용불가
SELECT LENGTH(C3) FROM T_LONG;
DISTINCT 키워드
DISTINCT 중복되는 값을 한번만 고려
CREATE TABLE test (
c1 NUMBER
);
INSERT INTO test VALUES (1000);
INSERT INTO test VALUES (NULL);
INSERT INTO test VALUES (2000);
INSERT INTO test VALUES (NULL);
INSERT INTO test VALUES (1000);
INSERT INTO test VALUES (2000);
COMMIT;
SELECT * FROM test;
SELECT
SUM(c1),
SUM(ALL c1),
SUM(DISTINCT c1)--중복값제외
FROM test;
###그룹함수와 NULL값
일반적으로 대부분의 그룹 함수는 NULL 값을 제외하고 계산합니다. 즉, 그룹 함수가 적용되는 열에서 NULL 값은 무시됩니다. 다만 몇 가지 함수는 예외적으로 NULL 값을 처리할 수 있습니다. 주요 그룹 함수들의 NULL 처리 방법은 다음과 같습니다:
- SUM 함수: NULL 값을 무시하고 나머지 값들의 합을 계산합니다.
- AVG 함수: NULL 값을 무시하고 나머지 값들의 평균을 계산합니다. NULL 값을 가지는 행의 개수가 총 행의 개수에서 제외됩니다.
- COUNT 함수: NULL 값을 포함한 모든 행의 개수를 반환합니다.
- MAX 함수: NULL 값을 무시하고 나머지 값들 중 최댓값을 반환합니다.
- MIN 함수: NULL 값을 무시하고 나머지 값들 중 최솟값을 반환합니다.
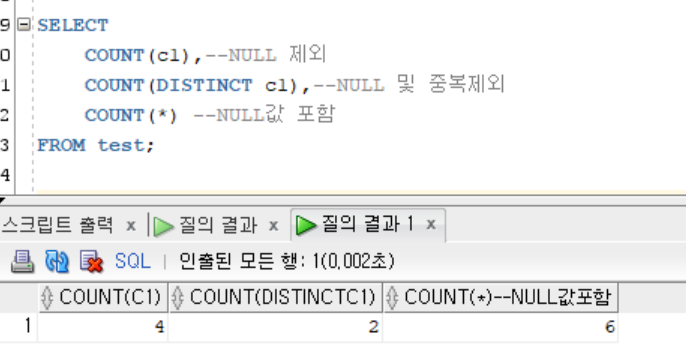
SELECT
COUNT(c1),--NULL 제외
COUNT(DISTINCT c1),--NULL 및 중복제외
COUNT(*) --아스타(*) 사용시 NULL값 포함
FROM test;
NULL값 고려하여 그룹함수를 사용하려면
--각 직원의 입사년도의 마지막 자리수와 해당 자리수를 2로 나눈 나머지를 계산
SELECT HIRE_DATE, TO_CHAR(HIRE_DATE, 'Y'), MOD(TO_CHAR(HIRE_DATE,'Y'),2)
FROM EMPLOYEES;
--커미션 비율이 있는 직원의 수를 세는 것
SELECT COUNT(CASE WHEN MOD(TO_CHAR(HIRE_DATE,'Y'),2) = 1 AND commission_pct IS NOT NULL THEN 1 END)
FROM EMPLOYEES;
--홀수 연도에 입사한 직원 중 커미션 비율이 있는 직원의 수를 세는 것
SELECT COUNT(*)
FROM EMPLOYEES
WHERE MOD(TO_cHAR(HIRE_DATE,'Y'),2) = 1
AND commission_pct IS NOT NULL;
SELECT COUNT(*)
FROM EMPLOYEES
WHERE MOD(EXTRACT(YEAR FROM HIRE_DATE),2) = 1
AND commission_pct IS NOT NULL;
###GROUP BY 절
값이 같은 행끼리 묶어서 그룹으로 지정. 그룹값의 순서는 없음. 하나의 행도없는 소그룹은 불가능.
WHERE절을 먼저 사용해서 필요없는 행을 미리 제외할 것
GROUP BY 절에 반드시 컬럼 또는 컬럼이 포함된 표현식이 기술
GROUP BY 절에 컬럼 별칭을 사용할 수 없음 컬럼 별칭은 SELECT 절에서 정의되므로
GROUP BY 절과 WHERE 절에 그룹 함수를 사용할 수 없음
그룹이 생성된 후에만 각 그룹에 대해 그룹 함수를 적용할 수 있으므로
GROUP BY 절은 그룹을 정의하는 절로서 GROUP BY 절의 수행이 끝나야 비로소 그룹이 생성됨
그룹 별 결과를 정렬할 필요가 있을 땐 반드시 ORDER BY 절 사용
--각부서별 사원들의 평균급여
SELECT department_id 부서,ROUND(AVG(salary)) 평균급여 ,COUNT(*) AS 사원수
--SELECT절은 그룹당 원하는 결과를 정의하는 곳 (팻말의 타이틀, 그룹함수)
FROM EMPLOYEES
GROUP BY department_id --GROUP BY 절에 반드시 컬럼 또는 컬럼이 포함된 표현식이 기술
ORDER BY department_id;
예제 p192
-- 회사 각 부서에 소속된 사원의 수를 부서번호와 함께 출력
SELECT department_id,COUNT(employee_id)
FROM EMPLOYEES
GROUP BY department_id
ORDER BY 1; --첫번째 컬럼으로 정리
--사원의 성의 길이에 따른사원 수를 출력
SELECT LENGTH(LAST_NAME)||'글자' AS 성, COUNT(*) 사원수
FROM EMPLOYEES
GROUP BY LENGTH(LAST_NAME);